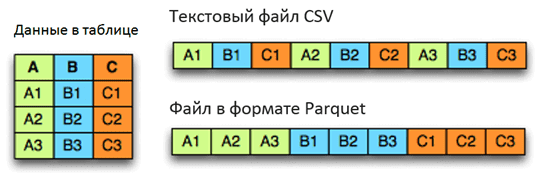
Apache Parquet — это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом хранения файлов Big Data и часто используется в Kafka, Spark и Hadoop.
Структура файла Apache Parquet
Из-за архитектурных особенностей структура представления информации в Parquet сложнее, чем, например, в JSON, который также часто используется для Big Data. В частности, уровни определения (definition levels) и уровни повторения (repetition levels) позволяют оптимально хранить пустые значения и эффективно кодировать данные, информацию о схеме в метаданные [2].
Уровни определения определяют количество необязательных полей в пути для столбца. Уровни повторения указывают, для какого повторяемого поля в пути, значение имеет повторение. Максимальные уровни определения и повторения могут быть вычислены из схемы. Эта степень вложенности определяет максимальное количество битов, необходимых для хранения уровней. В свою очередь, уровни определены для всех значений в столбце [1].
5 класс Работа № 13, задание 1 Паркет
Благодаря многоуровневой системе разбиения файлов на части реализуется параллельное исполнение важных Big Data операций (MapReduce, ввод-вывод, кодирование и сжатие) [2]:

- Row-group— логическое горизонтальное разбиение данных на строки для распараллеливания работы на уровне MapReduce. Не существует физической структуры, которая гарантирована для группы строк. Группа строк состоит из фрагмента столбца для каждого столбца в наборе данных.
- Column chunk— блок данных для столбца в определенной группе строк – разбиение для распределения операций ввода-вывода на уровне колонок, оптимизирует работу с жестким диском, записывая данные не по строкам, а по колонкам;
- Page— концептуально неделимая единица (с точки зрения сжатия и кодирования – разбиение колонок на страницы для распределения работ по кодированию и сжатию данных, например, с помощью кодеков snappy, gzip, lzo. Страницы содержат метаинформацию и закодированные данные.
Типы и представления данных в формате Паркет
Иерархически файл Parquet состоит из одной или нескольких групп строк. Группа строк содержит ровно один фрагмент столбца на столбец. Фрагменты столбцов содержат одну или несколько страниц.
Группы строк используются HDFS (распределенной файловой системой Apache Hadoop) для реализации концепции локальности данных, когда каждый узел кластера считывает лишь ту информацию, которая хранится непосредственно на его жестком диске.
В Apache Spark группа строк является единицей работы для каждой задачи MapReduce. При этом группа строк помещается в память, что следует учитывать при настройке размера группы – каков минимальный объём памяти, выделяемый на задачу на самом слабом узле кластера. Чтобы разбить входные данные на несколько row groups и эффективно распределить MapReduce-задачи по ресурсам кластера, можно использовать операцию разделения RDD-таблиц (Resilient Distributed Datasets) [2], которые являются объектами всех манипуляций с данными в Apache Spark – об этом мы рассказывали здесь.
Колоночные БД на примере Parquet
Поскольку типы данных влияют на объем занимаемого пространства, их стремятся минимизировать при проектировании форматов файла. Например, 16-разрядные числа явно не поддерживаются в формате хранения, поскольку они покрыты 32-разрядными числами с эффективным кодированием. Благодаря такой стратегии снижается сложность реализации чтения и записи формата. Parquet поддерживает следующие типы данных [1]:
- BOOLEAN – 1-битный логический;
- INT32 – 32-битные подписанные числа;
- INT64 – 64-битные подписанные числа;
- INT96 – 96-битные подписанные числа;
- FLOAT – IEEE 32-битные значения с плавающей точкой;
- DOUBLE – IEEE 64-битные значения с плавающей точкой;
- BYTE_ARRAY – произвольно длинные байтовые массивы.
Метаданные файла Apache Parquet
Формат Parquet явно отделяет метаданные от данных, что позволяет разбивать столбцы на несколько файлов, а также иметь один файл метаданных, ссылающийся на несколько файлов паркета. Метаданные записываются после значащих данных, чтобы обеспечить однопроходную запись. Таким образом, сначала прочитаются метаданные файла, чтобы найти все нужные фрагменты столбцов, которые дальше будут прочтены последовательно [1].
При повреждении метаданных сам файл теряется – данное правило актуально также в случае столбцов и страниц [2]:
- при повреждении метаданных столбца, потеряется этот фрагмент столбца, но его фрагменты в других группах строк останутся неизменны;
- при повреждении заголовка страницы, остальные страницы в этом столбце также будут потеряны;
- если данные на странице повреждены, эта страница теряется.
Таким образом, файл с небольшими группами строк является более устойчивым к повреждению. Однако, в этом случае размещение метаданных в конце файла будет проблемой, т.к. при возникновении сбоя при записи метаданных, все записанные данные станут нечитаемыми. Это можно исправить, записав метаданные файла в каждую N-ю группу строк. Метаданные каждого файла будут включать все группы строк, написанные до сих пор. Комбинируя это с маркерами синхронизации, можно восстановить частично записанные файлы [1].

Сжатие, кодирование и отображение файлов Big Data в формате Parquet
В формате Parquet сжатие больших данных выполняется столбец за столбцом, что позволяет использовать разные схемы кодирования для текстовых и целочисленных данных, в т.ч. вновь изобретенные. Также, благодаря колоночной структуре, формат Parquet существенно ускоряет процесс работы с данными, поскольку можно считывать не весь файл, а лишь необходимые столбцы, т.к. на практике для аналитических задач в конкретный момент нужны лишь несколько колонок. Кроме того, такое структурирование информации упрощает сжатие и кодирование данных за счёт их однородности и похожести [2]. В связи с этим, по сравнению с Avro и JSON, другими популярными форматами Big Data, Паркет быстрее сохраняет и сжимает данные, а также занимает меньше дискового пространства [3].
Источники
- https://ru.bmstu.wiki/Apache_Parquet
- https://habr.com/ru/company/wrike/blog/279797/
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/
Источник: www.bigdataschool.ru
Parquet что это такое и зачем пригодился?

Недавно мне потребовалось сделать большую выборку данных (несколько млн. записей) возник вопрос, как сохранить полученный результат для последующей обработки, т.к. на Hive выгрузить такой объем не представлялось возможным. Задача была решена с помощью DS-машины(DatalabAI), c использованием формата хранения данных — Parquet.
Отвечу на вопросы:
- Какие бывают форматы данных
- Для чего нужны разные форматы
- Чем лучше Parquet
- Примеры работы на практике с форматом Parquet
Обработка больших данных значительно увеличивает нагрузку на систему хранения. Hadoop хранит данные избыточно для достижения отказоустойчивости. Кроме дисков, нагружаются процессор, сетевые ресурсы, системы ввода-вывода данных. По мере роста объема данных значительно увеличивается и стоимость их обработки и хранения.
Различные форматы файлов в Hadoop используются для решения именно этих проблем. Выбор подходящего формата файла может дать существенные преимущества:
- Более быстрое время чтения.
- Более быстрое время записи.
- Разделяемые файлы.
- Поддержка эволюции схем.
- Расширенная поддержка сжатия
В Hadoop поддерживаются различные форматы файлов
Текстовые / CSV-файлы – повсеместно распространенный формат для обмена данными между Hadoop и внешними системами. Файлы в данном формате занимают значительный объем места так как не поддерживают сжатия, что приводит к существенным затратам на чтение данных файлов. Структура файла жестко связана с последовательностью полей и не хранит метаданные. Человеко-читаемый формат.
Записи в формате JSON – в отличие от CSV каждая строка представляет JSON базу данных, что позволяет разделять файл на части. Метаданные хранятся совместно с данными, что позволяет эволюционировать схеме. Также, как и CSV не поддерживает сжатие и занимает значительный объем места. Человеко-читаемый формат.
Файлы Avro — универсальный формат хранения данных в Hadoop. Данные хранятся построчно. Метаданные хранятся с данными, позволяют задавать независимую схему чтения данных. Можно переименовывать, удалять, изменять, добавлять типы данных полей. Поддерживают сжатие блоков.
RC-файлы — первый столбчатый формат в Hadoop, обладает значительными возможностями сжатия. Повышает производительность, не позволяет менять структуру. Для сохранения файлов требуется значительный объем вычислений.
Файлы ORC – это значительно оптимизированный формат файлов RC. Достигнут выдающийся размер сжатия, но также не поддерживается эволюция схемы.
Файлы Parquet – вариант столбчатых форматов, был придуман основателем Hadoop Дагом Каттингом в проекте Trevni. Также, как и все колончатые форматы обладает преимуществами сильного сжатия данных. Поддерживает частичную эволюцию схемы. Бинарный формат.
Parquetиспользует архитектуру, основанную на «уровнях определения» и уровнях повторения, что дает возможность эффективно кодировать информацию. Очень эффективно сохраняются пустые значения. Метаданные хранятся отдельно от данных.
Благодаря многоуровневой системе разбиения файлов на части реализуется параллельное исполнение важных Big Data операций (MapReduce, ввод-вывод, кодирование и сжатие)
Parquet поддерживает следующие типы данных:

- BOOLEAN – 1-битный логический;
- INT32 – 32-битные подписанные числа;
- INT64 – 64-битные подписанные числа;
- INT96 – 96-битные подписанные числа;
- FLOAT – IEEE 32-битные значения с плавающей точкой;
- DOUBLE – IEEE 64-битные значения с плавающей точкой;
- BYTE_ARRAY – произвольно длинные байтовые массивы.
Чтобы показать, как это работает, я продемонстрирую на следующем наборе данных:
[‘banana’, ‘banana’, ‘banana’, ‘banana’, ‘banana’, ‘banana’, ‘banana’, ‘banana’, ‘apple’, ‘apple’, ‘apple’]
Почти все реализации Parquet используют для сжатия словарь по умолчанию.
Таким образом, закодированные данные выглядят следующим образом:
dictionary: [‘banana’, ‘apple’] indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Индексы в словаре дополнительно сжимаются алгоритмом кодирования повторов:
dictionary: [‘banana’, ‘apple’] indices (RLE): [(8, 0), (3, 1)]
Например исходные данные, которые занимают более 1 Гб в pandas.DataFrame, со сжатием с помощью словаря занимает всего 1.5 MB
Таким образом формат Parquet:
- доступный формат для любого проекта в экосистеме Hadoop, независимо от выбора платформы обработки данных, модели данных или языка программирования
- Сокращает количество операций ввода-вывода.
- Извлекает определенные столбцы, к которым вам нужно получить доступ.
- Занимает меньше места.
Pyspark по умолчанию поддерживает Parquet в своей библиотеке, поэтому нам не нужно добавлять какие-либо библиотеки зависимостей.
Перехожу к практическим задачам, все примеры буду делать на DS машине(DatalabAI).
Создание тестового фрейма данных
Запускаю PySpark Notebook и открываю новую Spark сессию:
import pyspark from pyspark.sql import SparkSession spark=SparkSession.builder .appName(«parquetFile»).getOrCreate()
Формирую тестовый набор данных используя списки данных
data =[(«Иванов»,»Иван»,»Иванович»,»11-11-11″,»М»,50000), («Петрова»,»Мария»,»Петровна»,»22-22-22″,»Ж»,50000), («Рублев»,»Рубль»,»Рублевич»,»33-33-33″,»М»,60000), («Сидорова»,»Анна»,»Сидоровна»,»44-44-44″,»Ж»,50000), («Рыбакова»,»Мария»,»Рыбаковна»,»55-55-44″,»Ж»,40000)] columns=[«фамилия»,»имя»,»отчество»,»телефон»,»пол»,»зарплата»]
С помощью метода DataFrame и ранее подготовленных списков создаю тестовый DataFrame
df=spark.createDataFrame(data,columns) df.show() +———+——+———+———+—+———+ | фамилия| имя| отчество| телефон|пол|зарплата| +———+——+———+———+—+———+ | Иванов| Иван| Иванович|11-11-11| М| 50000| | Петрова|Мария| Петровна|22-22-22| Ж| 50000| | Рублев|Рубль| Рублевич|33-33-33| М| 60000| |Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000| |Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000| +———+——+———+———+—+———+
Сохранение фрейма данных в формат файла Parquet
Теперь создам файл в формате Parquet из фрейма данных. Для этого вызываю функцию parquet() в качестве параметра передаю путь и имя файла, обратите внимание на режим mode(«overwrite») он заставит систему перезаписать файл в случае если такой уже существует:
df.write.mode(«overwrite») .parquet(r»/tmp/output/people.parquet»)
В результате получаю каталог с именем people.parquet и содержащий файлы Parquet:


Если есть необходимость добавить данные в существующий файл можно использовать режим mode(‘append’):
df.write.mode(‘append’).parquet(«/tmp/output/people.parquet»)
Чтение данных из файла Parquet в датафрейм
Привожу пример чтения данных:
df2=spark.read.parquet(«/tmp/output/people.parquet») df2.show() +———+——+———+———+—+———+ | фамилия| имя| отчество| телефон|пол|зарплата| +———+——+———+———+—+———+ | Иванов| Иван| Иванович|11-11-11| М| 50000| | Петрова|Мария| Петровна|22-22-22| Ж| 50000| | Рублев|Рубль| Рублевич|33-33-33| М| 60000| |Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000| |Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000| +———+——+———+———+—+———+
Выполнение SQL-запросов DataFrame на Parquet файле
Загружаю наш parquet файл в датафрейм и создаю временное представление, далее считываю данные с помощью SQL запроса:
df=spark.read.parquet(«/tmp/output/people.parquet») df.createOrReplaceTempView(«ParquetTable») df2 = spark.sql(«select * from ParquetTable where `зарплата` = 40000 «) df2.show() +———+——+———+———+—+———+ | фамилия| имя| отчество| телефон|пол|зарплата| +———+——+———+———+—+———+ |Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000|
Создание таблицы из Parquet файла без использования датафрейма.
Создам временную таблицу из parquet файла с помощью SQL команды и далее прочитаю информацию из нее:
spark.sql(«CREATE TEMPORARY VIEW PERS USING parquet OPTIONS (path «/tmp/output/people.parquet»)») spark.sql(«SELECT * FROM PERSON»).show() +———+——+———+———+—+———+ | фамилия| имя| отчество| телефон|пол|зарплата| +———+——+———+———+—+———+ | Иванов| Иван| Иванович|11-11-11| М| 50000| | Петрова|Мария| Петровна|22-22-22| Ж| 50000| | Рублев|Рубль| Рублевич|33-33-33| М| 60000| |Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000| |Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000| +———+——+———+———+—+———+
Создание таблицы в формате Parquetна Hive

Для того, чтобы узнать путь созданной таблицы, использую команду, приведенную ниже, путь будет находиться в параметре location:

Далее привожу пример чтения созданной таблицы на DS машине и сохранение в CSV файл. Обратите внимание на знак «*», он обязателен, т.к. по умолчанию создается партицированный parquet файл. После прочтения таблицы в датафрейм, преобразую его в формат Pandas и сохраняю в формате в CSV:
df=spark.read.options(inferSchema=»True»,header=True») .parquet(r»hdfs://arnsdpsbx/user/team/team_sva_oarb/hive/tablename/*») df_res = spark_df.toPandas() df_res.to_csv(‘test.csv’, sep=’~’, encoding=’cp1251′, index = False)
Рассказал про файлы данных apache parquet в Spark, чем отличаются от других форматов, а также показал как работать с данными файлами на практике.
Источник: newtechaudit.ru
Урок 4
Моделирование в среде графического редактора
Часто объект, подлежащий моделированию, можно разбить на более мелкие детали. Дом состоит из кирпичей или строительных блоков, механизм — из отдельных узлов. Если разработать набор типовых деталей, то на его основе можно создавать разные объекты. Такая деятельность получила название конструирования.

Конструирование — один из способов моделирования. Оно предполагает разработку совместимых типовых элементарных объектов (деталей) и создание более сложных объектов из этих деталей.
Этот процесс упрощается, если использовать компьютер. Для моделирования из любых готовых элементов удобно создать в любой графической среде так называемое меню готовых форм. Иногда для создания такого меню требуется много времени. Но затраты оправдываются. Меню готовых форм облегчает работу и освобождает время для творчества.
На примере задачи «Моделирование паркета» рассмотрим этапы создания на компьютере меню типовых совместимых деталей и конструирование из них.
ЗАДАЧА 1.10. Моделирование паркета
I этап. Постановка задачи
ОПИСАНИЕ ЗАДАЧИ
В Санкт-Петербурге и его окрестностях расположены великолепные дворцы-музеи, в которых собраны произведения искусства великих русских и европейских мастеров. Помимо прекрасных творений живописи, скульптуры, мебели здесь сохранились уникальные образцы паркетов.
Эскизы этих паркетов создали великие зодчие. А реализовали их идеи мастеровые-паркетчики.
Паркет составляется из деталей разной формы и породы дерева. Детали паркета могут различаться по цвету и рисунку древесины.
Из этих деталей паркетчики на специальном столе собирают блоки, совместимые друг с другом. Из этих блоков уже в помещении на полу компонуется реальный паркет.
Одна из разновидностей паркетов — из правильных геометрических фигур (треугольников, квадратов, шестиугольников или фигур более сложной формы). В различных сочетаниях детали паркета могут дать неповторимые узоры. Представьте себя в роли дизайнера паркета, выполняющего заказ.
ЦЕЛЬ МОДЕЛИРОВАНИЯ
Разработать эскиз паркета.
ПРОМЕЖУТОЧНЫЕ ЦЕЛИ
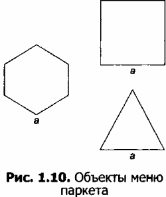
Разработать набор стандартных деталей паркета (рисунок 1.9). Разработать стандартный паркетный блок из деталей.

ФОРМАЛИЗАЦИЯ ЗАДАЧИ
Объектом моделирования является геометрический паркет, составленный из стандартного набора правильных многоугольников. Детали должны быть совместимы, то есть иметь единый типоразмер — длину стороны многоугольника а.
II этап. Разработка модели
ИНФОРМАЦИОННАЯ МОДЕЛЬ
КОМПЬЮТЕРНАЯ МОДЕЛЬ
Для моделирования набора совместимых деталей, паркетных блоков и паркета в целом можно использовать среду программирования на языке Лого или графический редактор.
Для обеспечения совместимости деталей используйте алгоритмы, разработанные ранее.
МОДЕЛЬ 1. Моделирование геометрических объектов с заданными свойствами для создания стандартного набора деталей паркета с совместимыми размерами
Полный набор деталей, необходимых для моделирования (рисунок 1.10), создайте самостоятельно, используя возможности поворотов и отражений фрагментов. Для создания квадрата, наклоненного на 60° и 30°, используйте собственный алгоритм.
Готовые фигуры раскрасьте, имитируя фактуру различных пород дерева.
МОДЕЛЬ 2. Моделирование паркетного блока
Созданное меню сохраните в файле «Меню паркета» и защитите от записи.
Количество деталей в паркетном блоке зависит от размера стороны многоугольника.
Блоки могут компоноваться из деталей одной, двух или трех разновидностей. На рисунке 1.11 изображены небольшие блоки из разного количества и ассортимента деталей.

МОДЕЛЬ 3. Компоновка паркета из созданных блоков
Паркет собирается из готовых блоков на полу. Образовавшиеся пустоты в углах и у стен заделываются деталями из стандартного набора.
Компьютерный эскиз паркета формируется по такому же принципу на рабочем поле графического редактора, с использованием его возможностей при работе с фрагментами рисунка.
Возможные образцы паркетов, составленных на основе созданных блоков, представлены на рисунке 1.12.

Ill этап. Компьютерный эксперимент
ПЛАН ЭКСПЕРИМЕНТА
1. Тестирование стандартного набора деталей — проверка совместимости.
2. Разработка паркетного блока.
3. Тестирование блоков — проверка их совместимости.
4. Моделирование эскизов паркета.
ПРОВЕДЕНИЕ ИССЛЕДОВАНИЯ
1. Разработайте несколько вариантов паркетного блока и эскизов паркета.
2. Предложите их на выбор заказчику.
IV этап. Анализ результатов
Если вид объекта не соответствует замыслу заказчика, вернуться к одному из предыдущих этапов: разработать другой набор деталей, или выбрать другие детали из набора, или создать другой блок из выбранных деталей.
Если вид паркета удовлетворяет исполнителя и (или) заказчика, принимается решение о разработке чертежей в реальном масштабе и подборе материалов.
ЗАДАЧА 1.11. Компьютерное конструирование из мозаики. Создание меню мозаичных форм
Как вы уже узнали из предыдущих тем, в графическом редакторе возможно конструирование.
У любого ребенка среди игрушек есть мозаика, из которой можно получить разнообразные узоры и изображения. Мозаика способствует развитию ребенка, и мозаичные построения — это первые попытки детей моделировать окружающий мир согласно своим представлениям. Но мозаика — не только детская игрушка.
Мозаичные узоры можно выполнять из метлахской и керамической плитки для украшения ванных комнат, например. Взяв за основу детали из ткани, можно сшить лоскутное одеяло или подушку.
Где еще используется моделирование (конструирование) из набора плоских деталей, подобных элементам паркета или мозаики? Все вы видели картонных кукол, у которых меняются платья, брюки и шляпки. Это своеобразный «набор юного модельера». Подобным моделированием занимаются не только дети, но и взрослые.
Милиционеры составляют фотороботы преступников из набора изображений глаз, усов и носов. С помощью компьютерной программы с набором картинок модных причесок парикмахер поможет клиенту подобрать прическу. Художнику или дизайнеру моделирование из плоских деталей поможет придумать модный рисунок ткани, создать многоцветный витраж.
Компьютер позволяет упростить процесс разработки композиций из набора типовых деталей. Например, создав в графическом редакторе меню мозаичных элементов и сохранив с параметром «только для чтения», вы сможете использовать его для создания новых композиций.
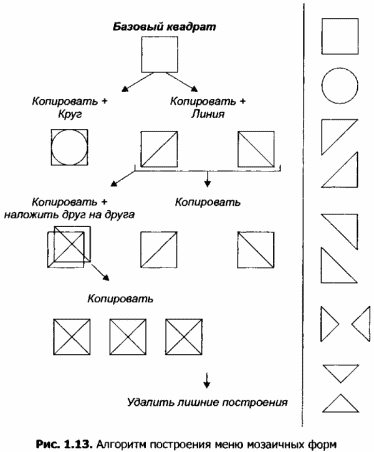
На рисунке 1.13 изображен алгоритм создания одного из таких меню.
ЗАДАЧА 1.12. Создание геометрических композиций из готовых мозаичных форм
Из многообразия мозаичных композиций можно выделить две разновидности: орнаментальную и сюжетную.
Основу орнаментальной мозаики составляет симметричный узор. Задачу моделирования такого узора можно отнести к типу «что будет, если..».
Орнамент начинают «выстраивать» из центра и дальше строят в произвольном порядке. При этом главным условием является соблюдение симметрии.
На рисунке 1.14 представлены образцы орнаментов.
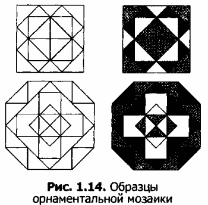
Орнаментальная мозаика уместна для одеяла, диванной подушки, детского коврика, витража. Компьютер позволит вам не только многократно переделывать узор, но и экспериментировать с готовым узором, раскрашивая его по-разному.
Сюжетная композиция представляет собой какую-либо сценку и содержит некоторые объекты, очертания которых предстоит реализовать из стандартного набора мозаичных элементов. Поэтому эту задачу можно отнести к типу «как сделать, чтобы. ». Например, при моделировании композиции «Под водой» для ванной комнаты придется создать объекты подводного мира: рыбок, водоросли и т. п. На рисунке 1.15 даны варианты изображения очертаний этих объектов.
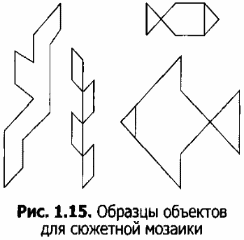
Создать объект по очертаниям — задача довольно сложная, а создание самих очертаний, похожих на оригиналы, — творческий процесс.
Источник: xn—-7sbbfb7a7aej.xn--p1ai