Системы спортивного паркета PST являются идеальным решением для устройства спортивных полов. Разумное сочетание цены и качества позволяют применять системы на объектах с невысоким бюджетом и высокими требованиями к полам.
Конструкции спортивного паркета используется для укладки в универсальных спортивных залах для игровых видов спорта, залах для занятия фитнесом, боксом и восточными единоборствами, залах для танцев, балетных и хореографических классах.
- Профессиональный уровень — WOODPLAY и WOODPLAY solid
- Тренировочный уровень — WOODACTION и WOODGAME
Обратная связь
Что бы узнать цены или запросить информацию, используйте данную форму обратной связи для обращения.
Ваше сообщение успешно отправлено
Ваше сообщение не отправлено
Источник: pstechnic.ru
Как использовать Parquet и не поскользнуться
УКЛАДКА ПАРКЕТА. ЗНАЕТЕ, ЧТО ЗА НЕОБЫЧНЫЙ ИНСТРУМЕНТ ПРИМЕНЯЕТСЯ НАМИ ДЛЯ УКЛАДКИ? #shorts
О хранении данных в Parquet-файлах не так много информации на Хабре, поэтому надеемся, рассказ об опыте Wrike по его внедрению в связке со Spark вам пригодится.
В частности, в этой статье вы узнаете:
— зачем нужен “паркет”;
— как он устроен;
— когда стоит его использовать;
— в каких случаях он не очень удобен.
Наверное, стоит начать с вопроса, зачем мы вообще начали искать новый способ хранения данных вместо предварительной агрегации и сохранения результата в БД и какими критериями руководствовались при принятии решения?
В отделе аналитики Wrike мы используем Apache Spark, масштабируемый и набирающий популярность инструмент для работы с большими данным (у нас это разнообразные логи и иные потоки входящих данных и событий). Подробнее о том, как у нас работает Spark, мы рассказывали ранее.
Изначально нам хотелось развернуть систему быстро и без особых инфраструктурных изощрений, поэтому мы решили ограничиться Standalone кластер-менеджером Спарка и текстовыми файлами, в которые записывали Json. На тот момент у нас не было большого входного потока данных, так что развёртывать hadoop и т.п. не было смысла.
- Мы стремились обойтись минимальным стеком технологий и сделать систему максимально простой, поэтому сразу отбросили Spark поверх hadoop, Cassandra, MongoDB, и другие, требующие особого менеджмента, способы хранения. Наши диски вполне шустрые и отлично справлялись с потоком данных, кроме того машины в кластере расположены близко друг к другу и связаны мощным сетевым интерфейсом.
- Входные данные у нас были плохо структурированы, поэтому выделить универсальную схему было сложно.
- Схема быстро эволюционировала из-за того, что мы постоянно добавляли новые события и улучшали трэкинг активности пользователей, поэтому выбрали json как формат данных и складывали их в обычные текстовые файлы.
- Мы стремились приблизиться к event-based аналитике. А в этом случае каждое событие должно быть максимально обогащено информацией, чтобы свести количество join операций к минимуму. На практике обогащение данных порождало всё больше колонок в схеме (это важный момент, мы к нему ещё вернёмся). Кроме того, из за большого количества событий совершенно разного рода, но связанных между собой и характеризуемых различными параметрами, схема также обзаводилась большим количество колонок и информация была достаточно разряженной.
- Мы работали с неизменяемыми данными: записали, а дальше только читаем.
После нескольких недель работы мы поняли, что с json данными работать неудобно и трудоемко: медленное чтение, к тому же при многочисленных тестовых запросов каждый раз Spark вынужден сначала прочесть файл, определить схему и только потом подобраться непосредственно к выполнению самого запроса. Конечно, путь Спарку можно сократить, заранее указав схему, но каждый раз проделывать эту дополнительную работу нам не хотелось.
Покопавшись в Спарке, мы обнаружили, что сам он активно использует у себя внутри parquet-формат.
Что такое Parquet
В parquet-файл записать их не получится, так как в первом случае у вас строка, а во втором сложный тип. Хуже, если система записывает входной поток данных в файл, скажем, каждый час. В первый час могут прийти события со строковыми value, а во второй — в виде сложного типа. В итоге, конечно, получится записать parquet файлы, но при операции merge schema вы наткнётесь на ошибку несовместимости типов.
Чтобы решить эту проблему, нам пришлось пойти на небольшой компромисс. Мы определили точно известную и гарантируемую поставщиком данных схему для части информации, а в остальном брали только верхнеуровневые ключи. При этом сами данные записывали как текст (зачастую это был json), который мы хранили в ячейке (в дальнейшем с помощью простых map-reduce операций это превращалось в удобный DataFrame) в случае примера выше ‘ “value”: ‘ превращается в ‘ “value”: “” ‘. Также мы столкнулись с некоторыми особенностями разбиения данных на части Спарком.
Как выглядит структура Parquet файлов
Parquet является довольно сложным форматом по сравнению с тем же текстовым файлом с json внутри.
Примечательно, что свои корни этот формат пустил даже в разработки Google, а именно в их проект под названием Dremel — об этом уже упоминалось на Хабре, но мы не будем углубляться в дебри Dremel, желающие могут прочитать об этом тут: research.google.com/pubs/pub36632.html.
Если коротко, Parquet использует архитектуру, основанную на “уровнях определения” (definition levels) и “уровнях повторения” (repetition levels), что позволяет довольно эффективно кодировать данные, а информация о схеме выносится в отдельные метаданные.
При этом оптимально хранятся и пустые значения.
Структура Parquet-файла хорошо проиллюстрирована в документации:
Файлы имеют несколько уровней разбиения на части, благодаря чему возможно довольно эффективное параллельное исполнение операций поверх них:
Row-group — это разбиение, позволяющее параллельно работать с данными на уровне Map-Reduce
Column chunk — разбиение на уровне колонок, позволяющее распределять IO операции
Page — Разбиение колонок на страницы, позволяющее распределять работу по кодированию и сжатию
Если сохранить данные в parquet файл на диск, используя самою привычную нам файловую систему, вы обнаружите, что вместо файла создаётся директория, в которой содержится целая коллекция файлов. Часть из них — это метаинформация, в ней — схема, а также различная служебная информация, включая частичный индекс, позволяющий считывать только необходимые блоки данных при запросе. Остальные части, или партиции, это и есть наши Row group.
Для интуитивного понимания будем считать Row groups набором файлов, объединённых общей информацией. Кстати, это разбиение используется HDFS для реализации data locality, когда каждая нода в кластере может считывать те данные, которые непосредственно расположены у неё на диске. Более того, row group выступает единицей Map Reduce, и каждая map-reduce задача в Spark работает со своей row-group. Поэтому worker обязан поместить группу строк в память, и при настройке размера группы надо учитывать минимальный объём памяти, выделяемый на задачу на самой слабой ноде, иначе можно наткнуться на OOM.
В нашем случае мы столкнулись с тем, что в определённых условиях Spark, считывая текстовый файл, формировал только одну партицию, и из-за этого преобразование данных выполнялось только на одном ядре, хотя ресурсов было доступно гораздо больше. С помощью операции repartition в rdd мы разбили входные данные, в итоге получилось несколько row groups, и проблема ушла.
Column chunk (разбиение на уровне колонок) — оптимизирует работу с диском (дисками). Если представить данные как таблицу, то они записываются не построчно, а по колонкам.
Представим таблицу: 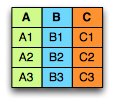
Тогда в текстовом файле, скажем, csv мы бы хранили данные на диске примерно так: 
В случае с Parquet: 
Благодаря этому мы можем считывать только необходимые нам колонки.
Из всего многообразия колонок на деле аналитику в конкретный момент нужны лишь несколько, к тому же большинство колонок остается пустыми. Parquet в разы ускоряет процесс работы с данными, более того — подобное структурирование информации упрощает сжатие и кодирование данных за счёт их однородности и похожести.
Каждая колонка делится на страницы (Pages), которые, в свою очередь, содержат метаинформацию и данные, закодированные по принципу архитектуры из проекта Dremel. За счёт этого достигается довольно эффективное и быстрое кодирование. Кроме того, на данном уровне производится сжатие (если оно настроено). На данный момент доступны кодеки snappy, gzip, lzo.
Есть ли подводные камни?
За счёт “паркетной” организации данных сложно настроить их стриминг — если передавать данные, то полностью всё группу. Также, если вы утеряли метаинформацию или изменили контрольную сумму для Страницы данных, то вся страница будет потеряна (если для Column chank — то chank потерян, аналогично для row group). На каждом из уровней разбиения строятся контрольные суммы, так что можно отключить их вычисления на уровне файловой системы для улучшения производительности.
Выводы:
Достоинства хранения данных в Parquet:
- Несмотря на то, что они и созданы для hdfs, данные могут храниться и в других файловых системах, таких как GlusterFs или поверх NFS
- По сути это просто файлы, а значит с ними легко работать, перемещать, бэкапить и реплицировать.
- Колончатый вид позволяет значительно ускорить работу аналитика, если ему не нужны все колонки сразу.
- Нативная поддержка в Spark из коробки обеспечивает возможность просто взять и сохранить файл в любимое хранилище.
- Эффективное хранение с точки зрения занимаемого места.
- Как показывает практика, именно этот способ обеспечивает самую быструю работу на чтение по сравнению с использованием других файловых форматов.
- Колончатый вид заставляет задумываться о схеме и типах данных.
- Кроме как в Spark, Parquet не всегда обладает нативной поддержкой в других продуктах.
- Не поддерживает изменение данных и эволюцию схемы. Конечно, Spark умеет мерджить схему, если у вас она меняется со временем (для этого надо указать специальную опцию при чтении), но, чтобы что-то изменить в уже существующим файле, нельзя обойтись без перезаписи, разве что можно добавить новую колонку.
- Не поддерживаются транзакции, так как это обычные файлы а не БД.
В Wrike мы уже достаточно давно используем parquet-файлы в качестве хранения обогащённых событийных данных, наши аналитики гоняют довольно много запросов к ним каждый день, у нас выработалась особая методика работы с данной технологией, так что с удовольствием поделимся опытом с теми, кто хочет попробовать parquet в деле, и ответим на все вопросы в комментариях.
P.S. Конечно, в последствии мы не раз пересматривали свои взгляды по поводу формы хранения данных, например, нам советовали более популярный Avro формат, но пока острой необходимости что-то менять у нас нет.
Для тех, кто до сих пор не понял разницу между строково-ориентированными данными и колончато-ориентированными, есть прекрасное видео от Cloudera,
а также довольно занимательная презентация о форматах хранения данных для аналитики.
- Блог компании Wrike
- Анализ и проектирование систем
- Big Data
Источник: habr.com
Система Кнауф-суперпол

Пол является неотъемлемой часть помещения и влияет не только на интерьер комнаты, но и на такие показатели, как температура и влажность воздуха, уровень теплозащиты. Поэтому международной компанией Кнауф, работающей в области производства стройматериалов, была разработана технология «Кнауф-суперпол», которая позволяет в короткие сроки выполнить качественный монтаж основания пола для дальнейшей укладки финишного покрытия.
Кнауф-суперпол — что это?
Кнауф-суперпол — это сборная конструкция или система, которая позволяет избежать «мокрых работ» по бетонной стяжке и, соответственно, уменьшить технологические перерывы, связанные с ее высыханием.
Элементы данной системы представляют собой склеенные гипсоволокнистые листы, на 50 мм смещенные относительно друг друга, благодаря чему по периметру образуются фальцы. Элемент кнауф-суперпол имеет общую толщину 20 мм и габаритные размеры 1.2×0.6 м. При такой толщине элемент пола весит немного, но сопротивляемость нагрузкам его поверхности достигает 20 МПа.
В качестве выравнивающего основания для элементов этой системы служит сухая засыпка из керамзита (с величиной фракции 0−5 мм), идеально заполняющая пространство и обладающая отличными термо- и звукоизоляционными, а также противопожарными характеристиками. В случае если гранулы керамзита будут больше, в тишине при ходьбе можно услышать легкий характерный хруст.
Система плавающего пола Кнауф, как ее еще называют, имеет по сравнению с традиционным выравниванием пола бетонной стяжкой ряд преимуществ:
- сокращение сроков монтажа. Система Кнауф-суперпол позволяет выполнить все работы буквально за несколько дней и не делать технологический перерыв на высыхание стяжки — к укладке чистового напольного покрытия можно приступать сразу же. Однако согласно рекомендации специалистов, не стоит трогать сухую стяжку несколько недель при толщине слоя засыпки больше 5 см, так как при такой толщине материал-засыпка даст усадку приблизительно 15 мм;
- главным преимуществом данной системы является отсутствие мокрых работ. Укладку сухой стяжки можно проводить без опасений в комнате, где ремонт уже окончен;
- звуко- и теплоизоляция. Керамзитовая засыпка препятствует проникновению шума и потере тепла;
- технология плавающего пола создает основание, которое готово к дальнейшему покрытию и не нуждается в дополнительном выравнивании мелких перепадов и неровностей, присущих песчано-цементной стяжке. А значит, экономит как время, так и средства. Так как основание, смонтированное из элементов Кнауф-суперпол, гладкое и ровное, на него можно стелить любой вид напольного покрытия, будь то линолеум, ламинат, плитка и так далее;
- в отличие от цементно-песчаной, сухая стяжка легкая и не нагружает перекрытия;
- непосредственно в сухой стяжке возможна прокладка труб или проводки.
Кнауф-суперпол укладывается по деревянным и бетонным перекрытиям в помещениях с неагрессивной средой. При укладке гидроизоляционного слоя применение данной системы возможно также в душевых и ванных комнатах. Особенно актуальна эта система в условиях снижения нагрузок на перекрытия или когда «мокрые» работы исключены.
Когда актуальна система Кнауф

Такие полы обладают широким спектром возможностей и позволяют в некоторых случаях обойтись небольшими затратами. Использовать сухую стяжку удобно:
- для устранения перепадов напольного основания свыше 40 мм. Это касается квартир старой застройки, где серьезный перепад высотных отметок является нормой;
- при монтаже электропроводки и системы водоснабжения после окончания ремонта;
- при ограниченных сроках проведения ремонтных работ;
- возможность проводить монтаж плавающего пола при низких температурах воздуха;
- при обветшании лагов.
Сооружение сухой стяжки
Работы по устройству сухой стяжки Knauf начинаются с замеров застилаемой площади пола и его горизонтального уровня. Сделать это можно при помощи строительного уровня, делая на стене засечки, указывающие на отклонение основания от горизонта. Засечки затем соединяются при помощи линейки и, таким образом, определяется необходимый слой керамзитовой засыпки.
Слой керамзита не должен превышать 100 мм. Нужный объем засыпки определяется из расчета 50 кг (1 мешок) засыпки для покрытия 1 м². Но это соотношение истинно в случае, когда полностью демонтировано предшествующее напольное покрытие.
Для монтажа плавающего пола понадобятся:
- клей «Супер ПВА»;
- элементы Кнауф-суперпол;
- самонарезающие винты по гипсоволокнистым листам;
- керамзитовая засыпка;
- пароизоляция;
- строительный скотч;
- кромочная лента или пенополиуретановый герметик.
Целесообразней кромочную ленту применять при показателе кривизны стен до 2 мм/м.п. Если этот показатель выше, лучше заполнить зазор между стеной и напольным основанием герметиком, излишки которой после застывания удаляются острым ножом.

После очистки основания пола от мелкого мусора и пыли расстилается пароизоляция (полиэтиленовая пленка) с нахлестом около 200 мм на стены. Поверх данной пленки с помощью густого гипсового раствора по отмеченному уровню устанавливаются маяки, например, алюминиевые рейки для укладки гипсокартонных плит, с шагом 900 мм. При укладке элементов системы по деревянному несущему основанию вместо полиэтиленовой пленки применяется гофрированная, парафинированная бумага или пергамин.
В пространство между маяками засыпается керамзитовая фракция, которая разравнивается строительным правилом. При формировании слоя свыше 5 см, засыпку необходимо тщательно утрамбовать.
Процесс укладки элементов Кнауф-суперпол начинается с угла. Смежная со стенами кромка подрезается. Все элементы монтируются по типу «шип-паз», при этом швы промазываются клеем и затем соединяются самонарезающими винтами с шагом 100 мм. Специалисты акцентируют, что в момент вкручивания винтов необходимо находится на том листе, который прикручивается.
Первый ряд элементов тщательно выравнивается по намеченному уровню, так как от этого будет зависеть монтаж остальных деталей системы. Регламентированный зазор между стеной и гипсоволокнистыми листами — 1 см — в дальнейшем заполняется пенополиуретановым герметиком. После того, как все листы смонтированы, готовое основание необходимо пропылесосить.
Нюансы

Данная конструкция основания пола позволяет в результате получить прочное покрытие, способное выдержать вес загруженного легкового автомобиля. Однако во избежание неприятных «сюрпризов» при эксплуатации собранного напольного покрытия профессионалы рекомендуют придерживаться нескольких правил:
- перед монтажом элементы системы Кнауф-суперпол должны адаптироваться в помещении, где будет производиться их укладка.
- храниться листы ГВЛ должны на ровной поверхности строго горизонтально.
- слой-основание керамзита не должен сильно отходить от горизонтального уровня.
- при устройстве основания из листов Кнауф во влажных помещениях помимо обязательной прокладки гидроизоляционной ленты вдоль стен, поверхность смонтированных элементов покрывается слоем гидроизоляции. К слову производитель Knauf их также выпускает.
- при чистовом покрытии тонким эластичным материалом основание покрывается слоем не более 2 мм самовыравнивающейся шпаклевки.
Как видно, процесс сооружения Кнауф-суперпола несложен, экономит не только время, но и средства, позволяет снизить нагрузки на перекрытия, повысить уровень шумо- и теплозащиты, а также выровнять напольное покрытие сложной конфигурации. Единственным минусом данного основания является его беззащитность перед влагой, в случае, если затопили соседи сверху. Однако для соседей снизу после монтажа Кнауф-суперпола дополнительная звукоизоляция станет подарком.

Фокин Андрей Евгеньевич
Источник: nashpol.com